Update
- 18 Oct 2022: We have completed the collection and annotation of AVSBench-V2. It contains ~7k multi-source videos covering 70 categories, and the ground truths are provided in the form of multi-label semantic maps (labels of V1 are also updated). We will release it as soon as possible.
- 13 Jul 2022: We are preparing the AVSBench-V2 which is much larger than AVSBench and will pay more attention to multi-source situation.
- 11 Jul 2022: The dataset has been uploaded to Google Drive and Baidu Netdisk (password: shsr), welcome to download and use!
- 10 Jul 2022: The AVSBench dataset has been released, please see Download for details.
- 10 Jul 2022: Code has been released here!
- 08 Jul 2022: Our paper is accepted to ECCV-2022. Camera-ready version and code will be released soon!
Audio-Visual Segmentation task
Hearing and sight are the two most important sensors for humans to perceive the world. Audio and visual signals are usually coexisting and complementary. For example, when we hear a dog bark or a siren wail,
we might see a dog or ambulance around accordingly.
Recently, audio-visual representation learning has attracted lots of attention and spawned some interesting tasks, such as Audio-Visual Correspondence (AVC), Audio-Visual Event Localization (AVEL) and video parsing (AVVP), Sound Source Localization (SSL), etc.
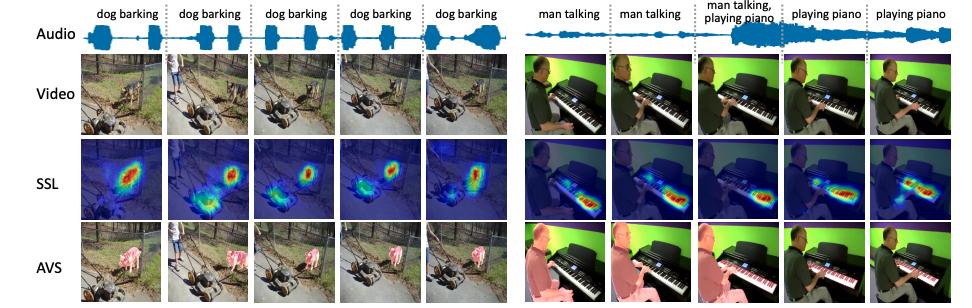
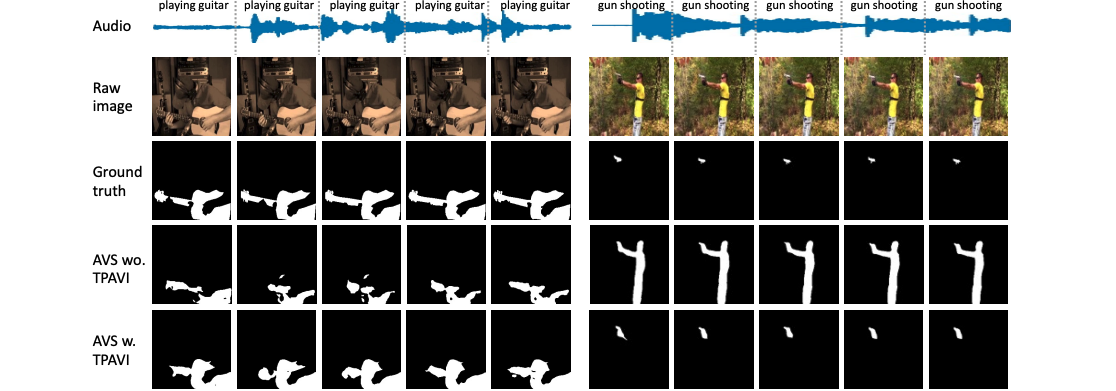
In this study, we explore the Audio-Visual Segmentation (AVS) problem that aims to generate pixel-level segmentation map of the object(s) that produce sound at the time of the image frame.
An illustration of the AVS task is shown in Figure 1. It is a fine-grained audio-visual learning problem, the pixel-level audio-visual correspondence/correlation/matching is supposed to learn.
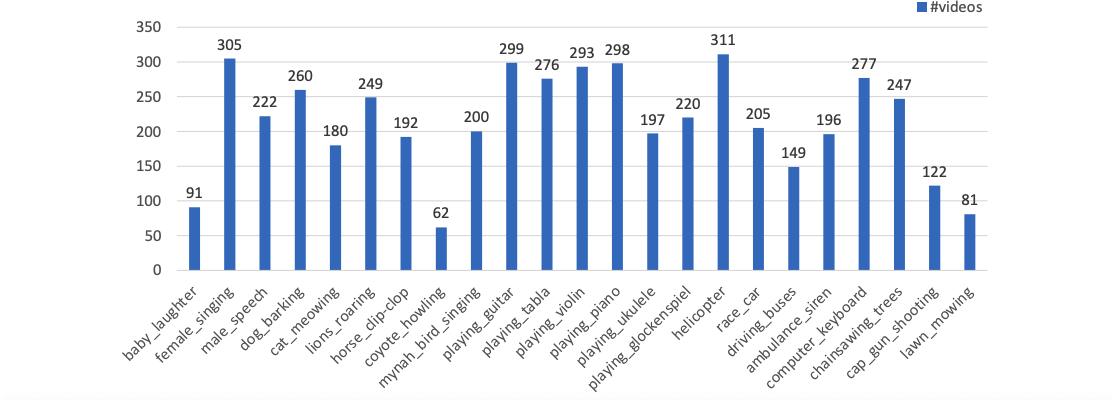
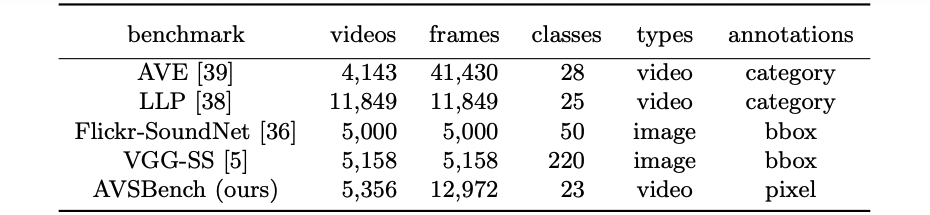
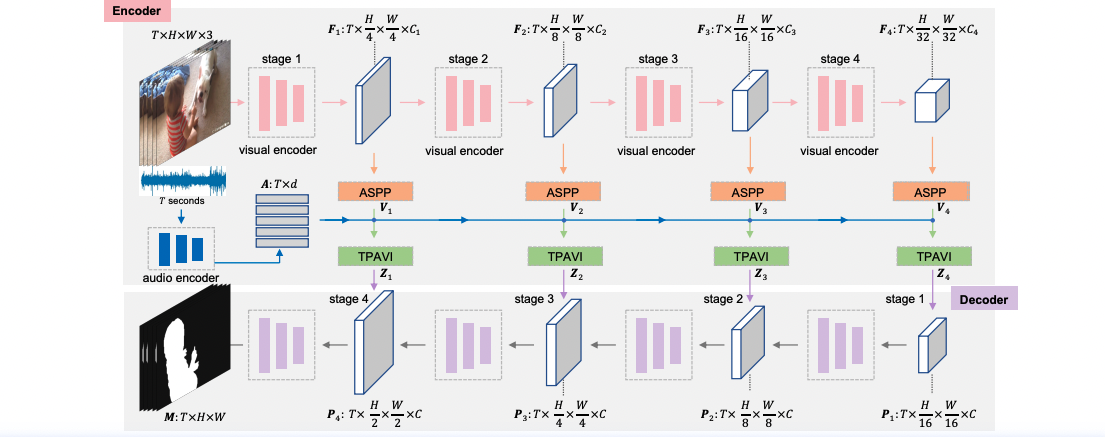
To facilitate this research, we propose the AVSBench dataset (details are introduced in the next section). With AVSBench, we study two settings of AVS: 1) semi-supervised single sound source segmentation (S4); 2) fully-supervised multiple sound source segmentation (MS3).